Git Workflow at WolfNet
I actually started writing this post years ago but never got around to publishing it. At CaringBridge we use a similar flow to that described at he end of this post with some slight differences. I would later come to find this flow described as “GitHub Flow” which is documented very cleanly at GitHub.com, though for the purposes of simplification they do not describe the use of forks.
When I first started working at WolfNet Technologies I was familiar with Git only by name. When I worked at the AAN (American Academy of Neurology) we used SVN and before that we used CVS. Something that always struck me as inefficient with SVN and CVS was the way that it stored a separate copy of every version of a file, as well as the meta data about the repository. Generally this didn’t cause storage issues on our individual machines which only ever had a single branch checked out a any given time. But it did result in a lot of space being used for the central repository server. On top of that because SVN and CVS are centralized rather than distributed, there was a lot of traffic back and forth if you needed to make a lot of commits or change branches. This of course was extremely slow and used a lot of bandwidth.
Initially I found Git a bit confusing, mostly because I was just getting to know Unix based systems and working with command line. Since Git is Unix based and I was using a Windows based machine things like SSH were incredibly frustrating to wrap my head around. Two things helped immensely in getting myself familiar with Git. One, I read Unix and Linux by Deborah S. Ray and Eric J. Ray, which was not only helpful in understand Git but open a lot of doors for me in terms of using command line interfaces and writing my own shell scripts, etc. By this time I was using Cygwin a lot and found it fantastic for improving my productivity. Second, I read Pro Git by Scott Chacon, which blew my mind as I learned about the simplicity yet incredible power and flexibility of Git. I very quickly became the developer on our team who was most familiar with Git, even though I was the newest to it.
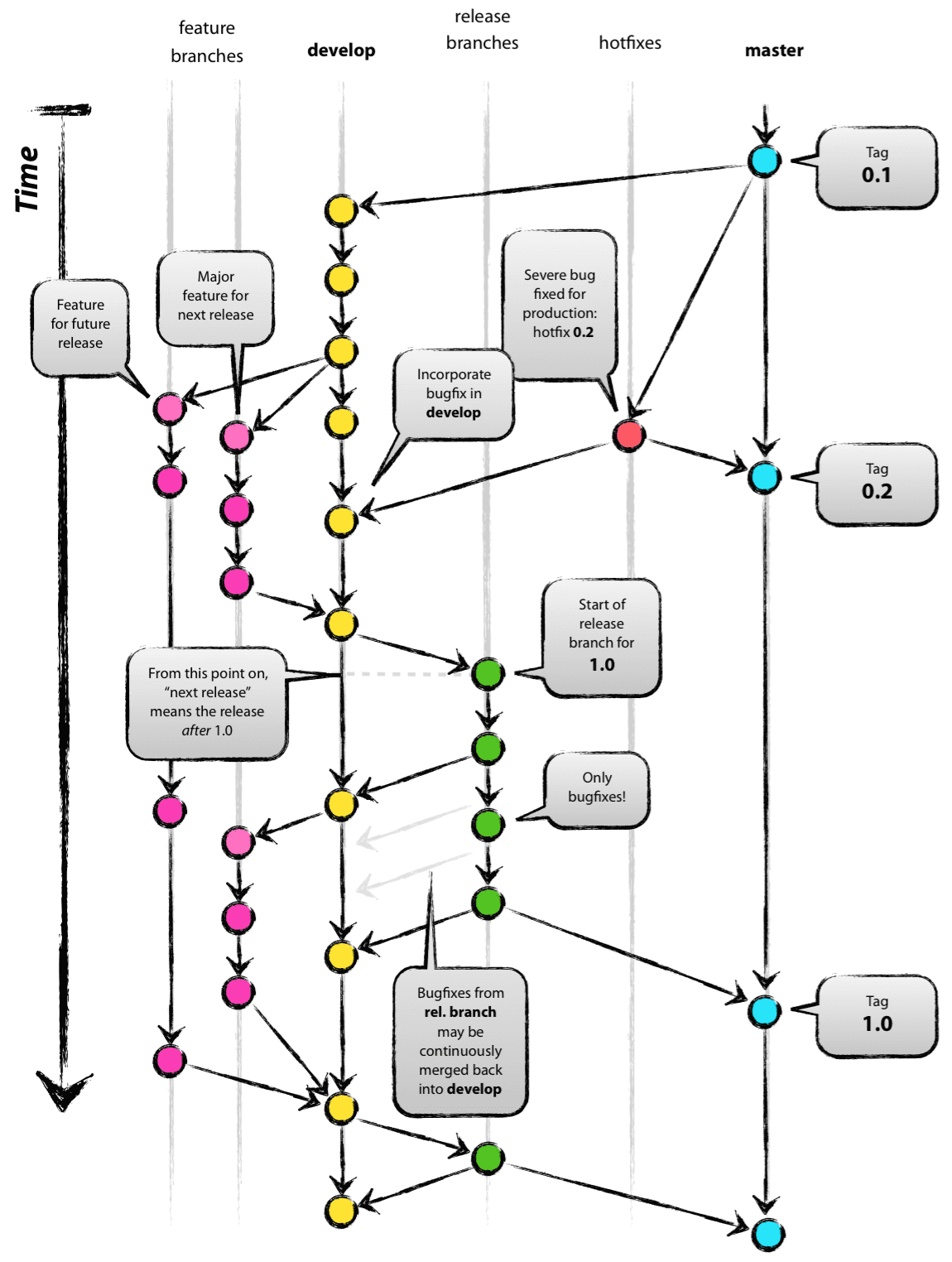
What I came to learn after I became familiar with Git was how completely underutilized and misused it was at WolfNet. Pretty much no one ever used branches to develop new functionality. All work was done in a “development” branch which were then re-based on top of the a “master” branch. In many changes the master branch was not used at all. It didn’t take long before through discussion and experimentation we started to implement a more formal workflow based on “Git Flow” as described by Vincent Driessen on is website nvie.com in an article titled “A Successful Git Branching Model”. I wont go into details about this process as it is very nicely documented in his article. We continued to used GitFlow in nearly all of our repositories for several years and on some repos continue to do so to this day.
As time went on I continued to advocate for doing code reviews within the team. We toyed around with several different approaches to code reviews. Given the pace at which we write code we decided the all hands on deck approach of everyone meeting and reviewing code at the same time was not effective. We were only able to review a little bit at a time and not everyone really understood what the context for most of the code was. Given that our Sys Admins had recently upgraded our Git server to include an instance of GitLab (an open source GitHub clone) we began exploring the possibility of adopting a pull request process for code reviews. With the advent of our new API and UI, a complete rewrite of our primary product, it was a good opportunity to approach our Git workflow a bit differently. With these two new repositories each developer forked an origin repository and began doing all of their development within their fork. Once ready they would submit their work via a pull request (called a “merge request” in GitLab) and this would then allow an opportunity for their code to be reviewed by another developer. This workflow offers numerous advantages with few drawbacks. One advantage is that the origin repository can be kept clean with only the master and release branches and tags. All feature branches are kept in each developers fork and they can name them however they want and have as many of them as they want.
At this point in my original article I went on to talk about our versioning and deployment process but I never finished. I will write a separate article about this topic in a different post since I still think what we came up with was pretty slick.